Retrieval-Augmented Generation (RAG) Pipeline for Financial Data Analysis
AI RAG LangChain LLM Finance
Overview
Large Language Models are powerful, but on their own they lack access to private, up-to-date, or domain-specific financial data.
This project solves that limitation by building a Retrieval-Augmented Generation (RAG) pipeline that grounds LLM responses in relevant financial documents.
The system allows users to ask natural-language questions about financial concepts, companies, or reports and receive context-aware, explainable answers sourced from real data rather than hallucinated knowledge.
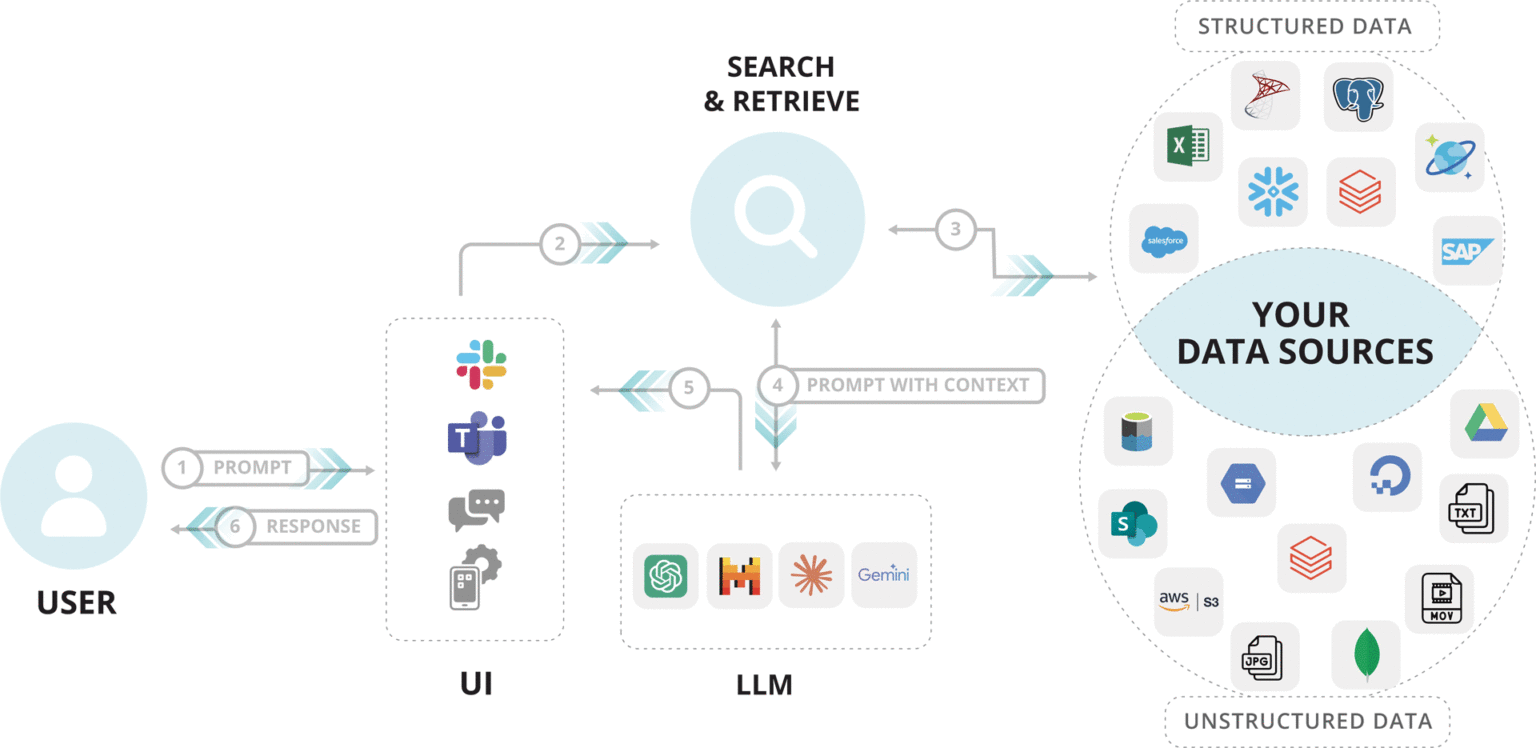
High-Level Architecture
At a high level, the system combines:
- A frontend that captures user queries
- A LangChain agent that orchestrates reasoning and tool usage
- A vector database for semantic document retrieval
- An LLM that generates grounded responses using retrieved context
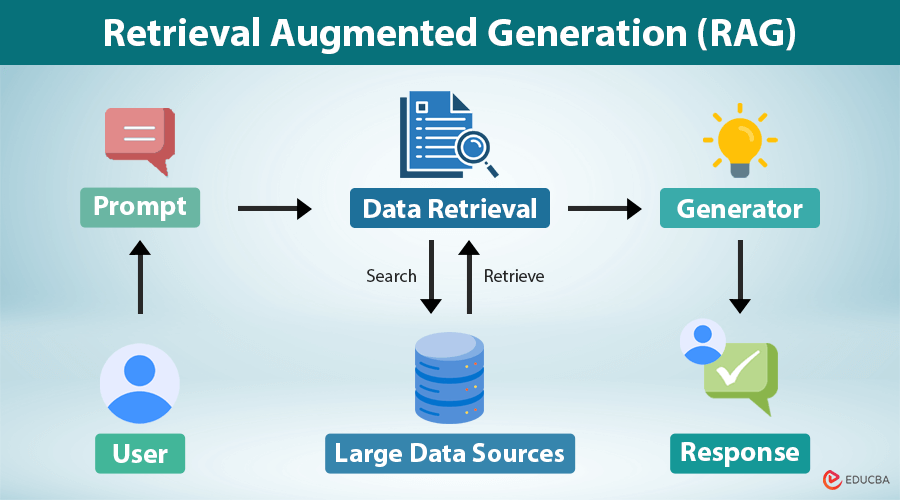
Step-by-Step Flow (Simple View)
- User asks a question (e.g., “What is EBITDA?” or “Explain recent earnings trends”)
- The query is sent to a backend Python FastAPI service
- The query is embedded and matched against a vector database
- Relevant document chunks are retrieved
- The LLM receives both the question and retrieved context
- A context-aware answer is streamed back to the user
Agent & Tooling Logic
The LangChain agent decides dynamically:
- Whether a tool is required (search, retrieval, calculator, etc.)
- Which documents are relevant
- How to structure the final response
Key Design Choices
- Tool Calling: Enables retrieval, calculations, and reasoning
- Memory: Maintains conversational context across turns
- Streaming Responses: Improves UX by returning partial answers in real time
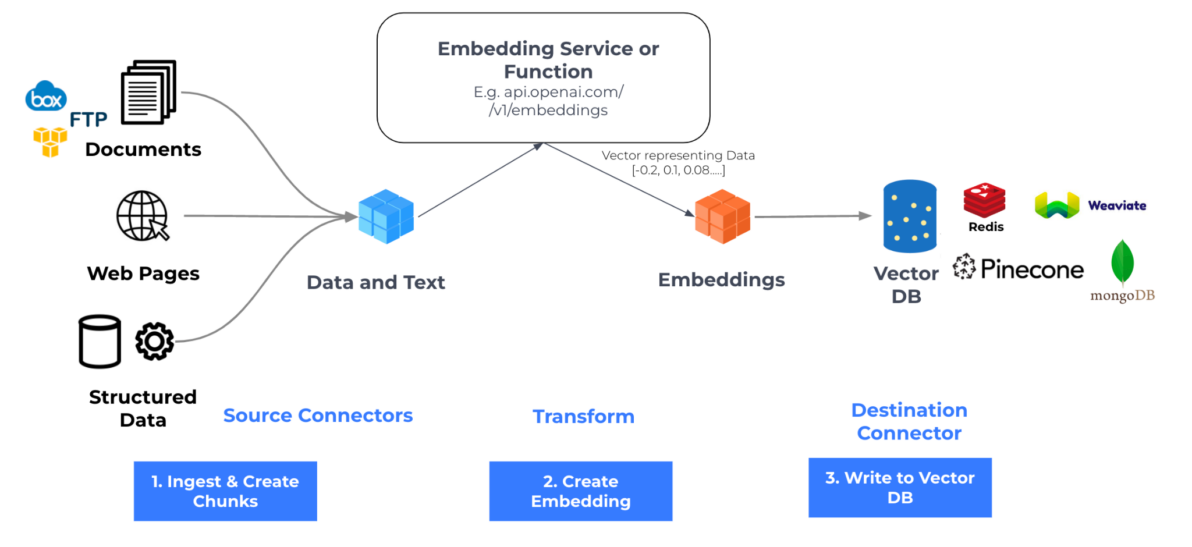
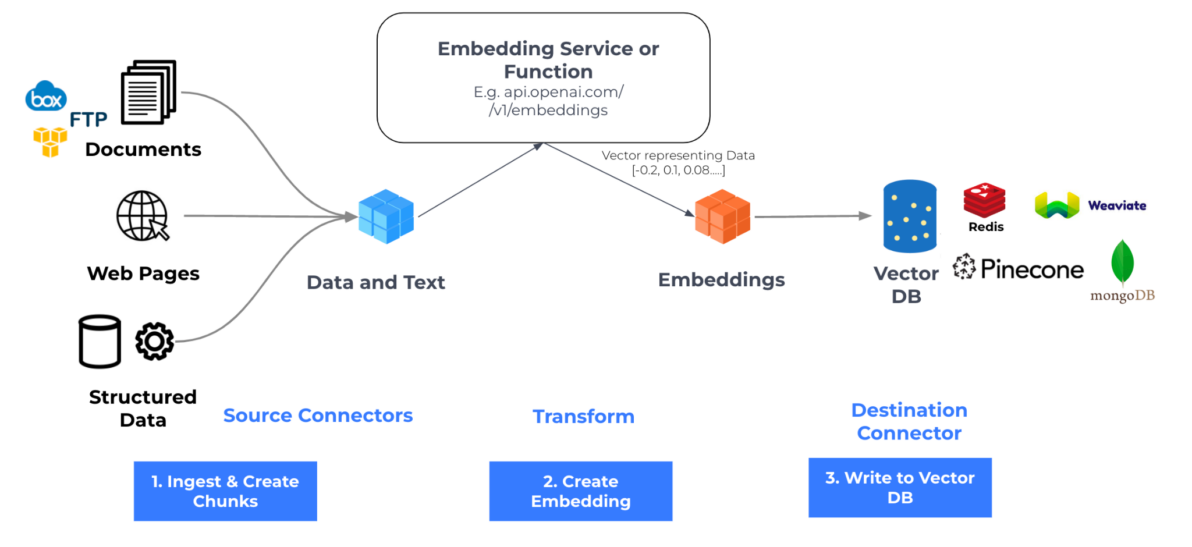
Vector Search & Retrieval
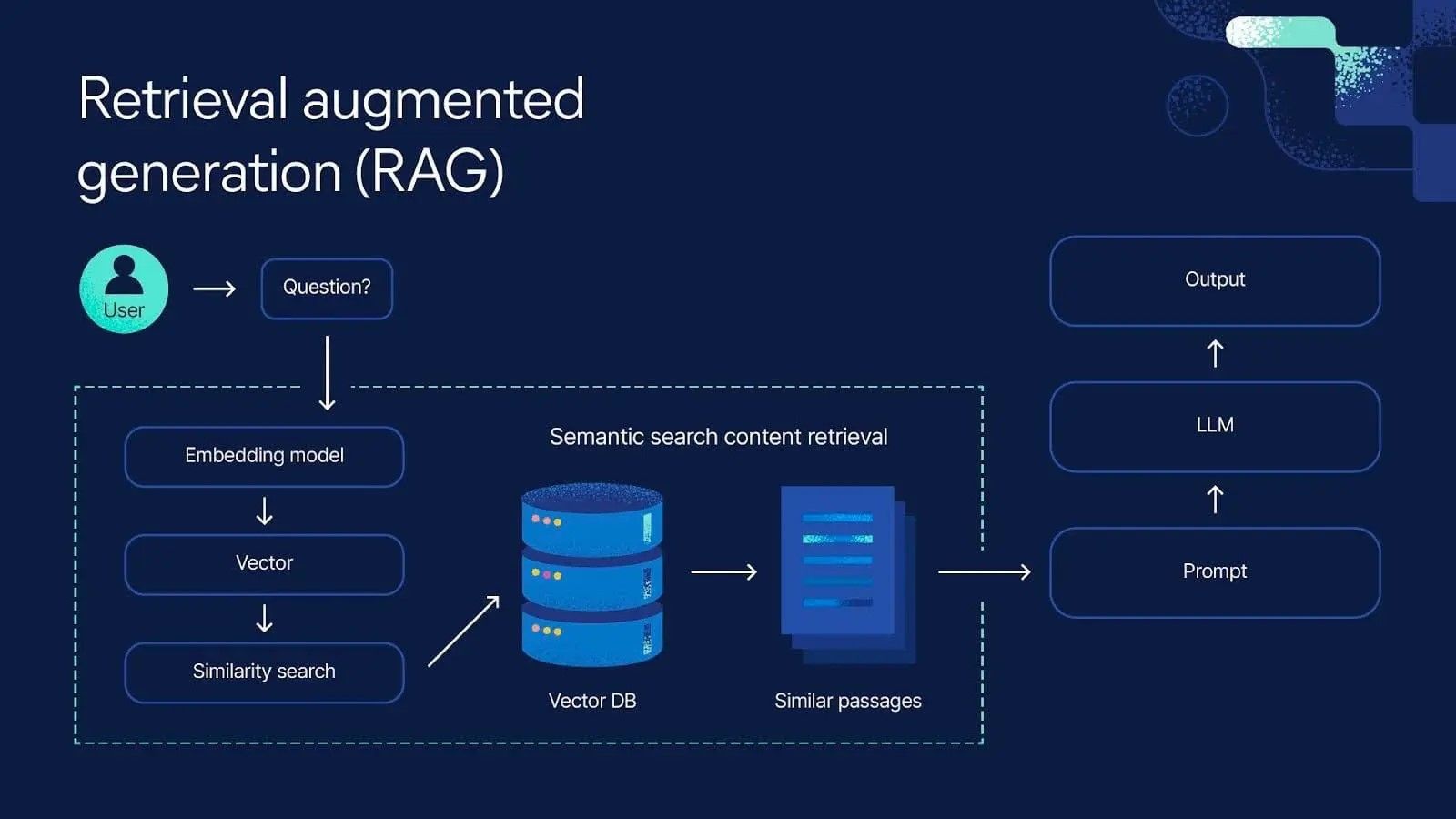
- Financial documents are split into chunks
- Each chunk is converted into vector embeddings
- Queries are embedded and matched using semantic similarity
- Only the most relevant chunks are passed to the LLM
This ensures answers are grounded in real data, not just model intuition.
Why RAG Matters for Finance
Traditional LLMs:
- Cannot access private financial documents
- Hallucinate facts
- Struggle with up-to-date market data
This RAG pipeline:
- Grounds answers in real financial sources
- Improves accuracy and trust
- Scales across reports, filings, and research notes
- Enables explainable AI for finance use cases
Key Features
- Context-aware financial Q&A
- Semantic document retrieval using embeddings
- Tool-based agent reasoning
- Streaming responses for better UX
- Modular and extensible architecture
Tech Stack
- Language: Python
- Frameworks: LangChain, FastAPI
- LLM: OpenAI API
- Vector Database: FAISS / ChromaDB
- Concepts: RAG, Tool Calling, Memory, Embeddings
Links
- GitHub Repository: https://github.com/ashik-ms/langChainAgent